Theory of Operations¶
Table of Contents
RackHD enables much of its functionality by providing PXE boot services to machines that will be managed, and integrating the services providing the protocols used into a workflow engine. RackHD is built to download a microkernel (a small OS) crafted to run tasks in coordination with the workflow engine. The default and most commonly used microkernel is based on Linux, although WinPE and DOS network-based booting is also possible.
RackHD was born from the realization that our effective automation in computing and improving efficiencies has come from multiple layers of orchestration, each building on a lower layer. A full-featured API-driven environment that is effective spawns additional wrappers to combined the lower level pieces into patterns that are at first experimental and over time become either de facto or concrete standards.
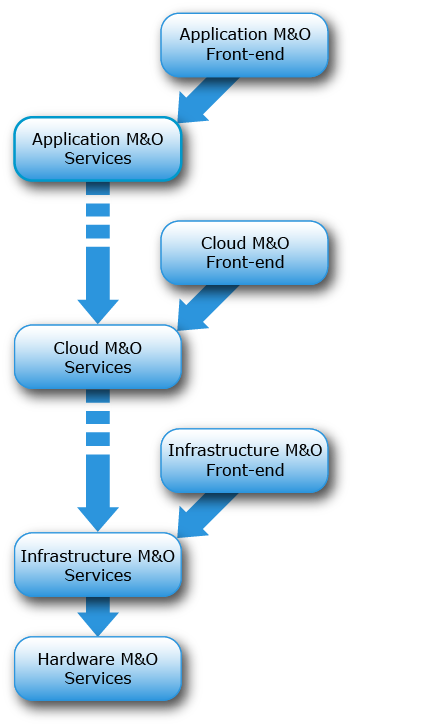
Application automation services such Heroku or CloudFoundry are service API layers (AWS, Google Cloud Engine, SoftLayer, OpenStack, and others) that are built overlying infrastructure. Those services, in turn, are often installed, configured, and managed by automation in the form of software configuration management: Puppet, Chef, Ansible, etc. To automate data center rollouts, managing racks of machines, etc - these are built on automation to help roll out software onto servers - Cobbler, Razor, and now RackHD.
The closer you get to hardware, the less automated systems tend to become. Cobbler and SystemImager were mainstays of early data center management tooling. Razor (or Hanlon, depending on where you’re looking) expanded on those efforts.
RackHD expands the capabilities of hardware management and operations beyond the mainstay features, such as PXE booting and automated installation of OS and software. It includes active metrics and telemetry, integration and annotated monitoring of underlying hardware, and firmware updating.
RackHD continues the extension by enabling automation by “playing nicely” with both existing and future potential systems, providing a consistent means of doing common automation and allowing for the specifics of various hardware vendors. It adds to existing open source efforts by providing a significant step the enablement of converged infrastructure automation.
Features¶
Bare Metal Server Automation with PXE¶
RackHD uses the Preboot Execution Environment (PXE) for booting and controlling servers. PXE is a vendor-independent mechanism that allows networked computers to be remotely booted and configured. PXE booting requires that DHCP and TFTP are configured and responding on the network to which the machine is attached.
RackHD uses iPXE as its initial bootloader. iPXE takes advantage of HTTP and permits the dynamic generation of iPXE scripts – referred to in RackHD as profiles – based on what the server should do when it is PXE booting.
Data center automation is enabled through each server’s Baseboard Motherboard Controller (BMC) embedded on the server motherboard. Using Intelligent Platform Management Interface (IPMI) to communicate with the BMC, RackHD can remotely power on, power off, reboot, request a PXE boot, and perform other operations.
Many open source tools, such as Cobbler, Razor, and Hanlon use this kind of mechanism. RackHD goes beyond this and adds a workflow engine that interacts with these existing protocols and mechanisms to let us create workflows of tasks, boot scripts, and interactions to achieve our full system automation.
The workflow engine supports RackHD responding to requests to PXE boot, like the above systems, and additionally provides an API to invoke workflows against one or more nodes. This API is intended to be used and composed into a larger system to allow RackHD to automate efforts sequences of tasks, and leverage that specifically for bare metal manangement. For more details on workflows, how to create them, and how to use them, please see Workflows in the RackHD API, Data Model, Feature.
RackHD includes defaults to automatically create and run workflows when it gets DHCP/PXE requests from a system it’s never seen previously. This special case is called Discovery.
Discovery and Geneaology¶
RackHD supports two modes of learning about machines that it manages. We loosely group these as passive and active discovery.
- Passive discovery is where a user or outside system actively tells RackHD that the system exists. This is enabled by making a post to the REST interface that RackHD can then add to its data model.
- Active discovery is invoked when a machine attempts to PXE boot on the network that RackHD is monitoring. As a new machine PXE boots, RackHD retrieves the MAC address of the machine. If the MAC address has not been recorded, RackHD creates a new record in the data model and then invokes a default workflow. To enable active discovery, you set the default workflow that will be run when a new machine is identified to one of the discovery workflows included within the system. The most common is the SKU Discovery workflow.
For an example, the “SKU Discovery” workflow runs through its tasks as follows:
- It runs a sub-workflow called ‘Discovery’
- Discovery is initiated by sending down the iPXE boot loader with a pre-built script to run within iPXE. This script then chainloads into a new, dynamically rendered iPXE script that interrogates the enabled network interfaces on the remote machine and reports them back to RackHD. RackHD adds this information to the machine and lookup records. RackHD then renders an additional iPXE script to be chainloaded that downloads and runs the microkernel. The microkernel boots up and requests a Node.js “bootstrap” script from RackHD. RackHD runs the bootstrap program which uses a simple REST API to “ask” what it should do on the remote host.
- The workflow engine, running the discovery workflow, provides a set of tasks to run. These tasks are matched with parsers in RackHD to understand and store the output. They work together to run Linux commands that interrogate the hardware from the microkernel running in memory. These commands include interrogating the machine’s BMC settings through IPMI, the installed PCI cards, the DMI information embedded in the BIOS, and others. The resulting information is then stored in JSON format as “catalogs” in RackHD.
- When it’s completed with all the tasks, it tells the microkernel to reboot the machine and sends an internal event that the basic bootstrapping process is finished
- The SKU Discovery workflow then performs a workflow task process called “generate-sku” that compares the catalog data for the node against SKU definition loaded into the system through the REST interface. If the definitions match, RackHD updates its data model indicating that the node belongs to a SKU. More information on SKUs, how they’re defined, and how they can be used can be found at SKUs.
- The task “generate-enclosure” interrogates catalog data for the system serial number and/or IPMI fru devices to determine whether the node is part of an enclosure (for example, a chassis that aggregates power for multiple nodes), and updates the relations in the node document if matches are found.
- The task “create-default-pollers” creates a set of default pollers that periodically monitor the device for system hardware alerts, built in sensor data, power status, and similar information.
- The last task (“run-sku-graph”) checks if there are additional workflow hooks defined on the SKU definition associated with the node, and creates a new workflow dynamically if defined.
You can find the SKU Discovery graph at https://github.com/RackHD/on-taskgraph/blob/master/lib/graphs/discovery-sku-graph.js, and the simpler “Discovery” graph it uses at https://github.com/RackHD/on-taskgraph/blob/master/lib/graphs/discovery-graph.js
Notes:
- No workflow is assigned to a PXE-booting system that is already known to RackHD. Instead, the RackHD system ignores proxy DHCP requests from booting nodes with no active workflow and lets the system continue to boot as specified by its BIOS or UEFI boot order.
- The discovery workflow can be updated to do additional work or steps for the installation of RackHD, to run other workflows based on the SKU analysis, or perform other actions based on the logic embedded into the workflow itself.
- Additional pollers exist and can be configured to capture data through SNMP. The RackHD project is set up to support additional pollers as plugins that can be configured and run as desired.
Telemetry, Events and Alerting¶
RackHD leverages its workflow engine to also provide a mechanism to poll and collect data from systems under management, and convert that into a “live data feed”. The data is cached for API access and published through AMQP, providing a “live telemetry feed” for information collected on the remote systems.
In addition to this live feed, RackHD includes some rudimentary alerting mechanisms that compare the data collected by the pollers to regular expressions, and if they match, create an additional event that is published on an “alert” exchange in AMQP. More information can be found at Pollers in the RackHD API, Data Model, Feature.
RackHD also provides notification on some common tasks and workflow completion. Additional detail can be found at Northbound Event Notification.
Additional Workflows¶
Other workflows can be configured and assigned to run on remote systems. For example, OS install can be set to explicitly power cycle (reboot) a remote node. As the system PXE boots, an installation kernel is sent down and run instead of the discovery microkernel.
The remote network-based OS installation process that runs from Linux OS distributions typically runs with a configuration file - debseed or kickstart. The monorail engine provides a means to render these configuration files through templates, with the values derived from the workflow itself - either as defaults built into the workflow, discovered data in the system (such as data within the catalogs found during machine interrogation), or even passed in as variables when the workflow was invoked by an end-user or external automation system. These “templates” can be accessed through the Monorail’s engine REST API - created, updated, or removed - to support a wide variety of responses and capabilities.
Workflows can also be chained together and the workflow engine includes simple logic (as demonstrated in the discovery workflow) to perform arbitrarily complex tasks based on the workflow definition. The workflow definitions themselves are accessible through the Monorail engine’s REST API as a “graph” of “tasks”.
For more detailed information on graphs, see the section on Workflows under our RackHD API, Data Model, Feature.
Workflows and tasks are fully declarative with a JSON format. A workflow task is a unit of work decorated with data and logic that allows it to be included and run within a workflow. Tasks are also mapped up “Jobs”, which is the Node.js code that RackHD runs from data included in the task declaration. Tasks can be defined to do wide-ranging operations, such as bootstrap a server node into a Linux microkernel, parse data for matches against a rule, and more.
For more detailed information on tasks, see the section on Workflow Tasks under our RackHD API, Data Model, Feature.